On Kalman filters and how I made them 20x faster using Rust
October 7, 2023
Python is generally fast enough — until it’s not. When you reach that point, there are several ways to speed up your Python code. However, one of the most effective approaches is to rewrite the bottleneck in a different language. Traditionally, that language has been C/C++. But now, there’s another contender entering the arena:
Rust.
That’s right; grab your sunglasses. We’re about to join the cool kids by re-implementing our code in Rust.
The problem
At my workplace, our primary product uses multiple cameras to track people in 3D in real-time. Each camera is designed to detect keypoints—think head, feet, knees, and so on—for each person in view, multiple times per second. These detections are then sent to a centralized application. Since we know the spatial positioning of the cameras, we can triangulate the position of these keypoints by integrating data from multiple cameras.

To grasp how we consolidate information from various cameras, let’s first look at what we can glean from just one camera. If we detect, for instance, a person’s nose in a camera frame (a 2D image), we know the direction in which the nose points from the camera’s perspective—but we can’t determine how far away it is. In geometric terms, we have a line of possible locations for the person’s nose in the 3D world.

We could make an educated guess about the distance based on the average human size, but that’s difficult, error-prone, and imprecise. A more accurate approach is to use multiple cameras. Each camera provides a line of possible locations for a keypoint; thus, by using just two cameras, we can find the intersection of those lines to pinpoint the keypoint’s 3D location.
However, this approach is not foolproof; several sources of uncertainty can compromise the accuracy:
- Cameras might not capture images simultaneously, causing each to deal with a slightly different version of the scene.
- Identifying keypoints is inherently inexact. Could you determine the exact pixel corresponding to someone’s left knee in a photo? Likely not—and neither can machine-learning algorithms. Calibrating the position and orientation of cameras is never perfect; even a minor discrepancy of a centimeter or two can introduce errors.
- Lens distortion is an inevitable aspect of camera technology. While you can correct for it, doing so is never 100% effective.
Adding more cameras could alleviate some of these issues. More lines mean a better intersection point, which can be found by minimizing a (weighted) least squares formula. But if you are like me, then you’re probably just about ready to scream the true solution:
Let’s go Bayesian
Kalman filters
In our situation, a Kalman filter can essentially be understood in these terms:
-
We start with an estimate of both the position and velocity of a keypoint, along with a certain degree of uncertainty.
-
As time progresses, this estimate changes—especially if we have an idea of the direction in which the keypoint is moving. However, the uncertainty associated with both the position and velocity will invariably increase. To illustrate, if I see someone moving and then close my eyes, I might guess their location 100 milliseconds later. But if you ask about their location or speed next Tuesday, I’d be clueless.
-
Each new observation serves to update our existing knowledge about the keypoint’s position and velocity. Due to the inherent imprecision of all observations, the updated estimates are a blend of our previous estimate and the new observation.
-
Formalize these steps and toss in some Gaussians, and you’ve got yourself a Kalman filter! We’re going to dive into the specifics right now, but if you’d rather not get into the math, feel free to skip ahead to the
</math>tag.
<math>
The Kalman filter can be thought of as a two-step process: the prediction step and the update step.
Predict step
To warm up, let’s focus on how to model a single, static keypoint. Imagine we have a position along with a covariance matrix . These represent the mean and variance of a random variable at the initial time .
As time passes, our estimated position remains unchanged, but the covariance matrix should grow. To model this, we can turn to Brownian motion and write where represents a Wiener process (or Brownian motion), and is the noise level. The expectaton for this is , while the variance evolves according to:
Things get more complicated when we introduce a velocity parameter . Viewing this from the perspective of a stochastic differential equation (SDE), the original equation was
Adding in the velocity this then becomes
We can integrate this by first integrating to obtain
Which we then can substitue to get
Finally integrating this we obtain
You’ll notice the last term is not Gaussian. Still, with some standard mathematical tricks (Itô’s Lemma), we find:
In summary, our predict step can be represented as:
While the math wasn’t overly complicated, the intricacy quickly scales with more complex stochastic differential equations. Analytical integration may not always be feasible, making numerical or Monte-Carlo methods an alternative, albeit costly, approach.
Fortunately, if our prediction is linear, we can simplify things considerably. In our case, the function is indeed linear. Let’s denote this map by . Now, we encapsulate both together into a single variable , with the covariance being a matrix. Ignoring the term, the update step simplifies to:
where . We use for the estimate of the state at step , acknowledging that we don’t know the actual value. As long as long as our model function is linear, this approximation will suffice. However if is nonlinear, then we’re in trouble, but we’ll see more on that later.

Update step
After the prediction step, we move from an initial state to an estimated . This is an estimate of the true state of the system at time , based on our estimate at time . At the same time, we observe the system and obtain a measurement of the system.
Unfortunately the measurement does not live in the same space as the state . For example, might represent a 2D observation while represents a position+velocity in 3D.
To go from the ‘model space’ to the ‘measurement space’ we introduce a matrix . In the context of tracking a koving keypoint for instance, this matrix is a matrix given blockwise as where is a matrixof zeros. This matrix is simply the act of ‘forgetting’ the velocity and only keeping the position.
Our goal is now to derive an estimate for the state at time by incorporating both the previous estimate and the observation . In order to do that, we lean on 3 assumptions:
- The estimate is accurate. That is, we assume is a sample of the distribution .
- The observation is a direct measurement of with an error , in other words is a sample of
- There is a matrix , known as the Kalman gain,such that
The last assumption is not really an assumption of the model, but more a convenience to make the math work out. With this assumption we can derive an ‘optimal’ estimate of the true state . None of these assumptions are realistic. For instance, in our simple Bayesian analysis of the prediction step we have already noted that the prediction step used by the Kalman filter is an approximation. The second point assumes that the measurement error is exactly Guassian, which is rarely true in practice. Nevertheless, these assumptions make for a good model that can actually be used for practical computations.

Deriving the optimal value of the Kalman gain is a little tricky, but we can relatively easily use the assumptions above to find a formula for the new error estimate . We can define as . Then we make several observations:
- By assumption .
- We can write as , where follows a normal distribution and is independent of the other random variables.
The rest is a straightforward computation using properties of covariance:
Now, let’s tackle the question of how to calculate the optimal value for the Kalman gain. To do this, we first need to clarify what “optimal” signifies in this setting. In this context optimal refers to the value of that minimizes the expected residual squared error . Using some tricks from statistics and matrix calculus it turns out that the opimal Kalman gain takes the following fomr:
where
which is just the covariance matrix of the residual .
In summary, using several assumptions we can use prior estimate and an observation to get an improved estimate . This is all a Kalman filter is: we alternate predict and update steps to always have an up-to-date estimate of the models state.
Unscented Kalman filters
To derive the prediction and update steps of the Kalman filter we had to make one ‘stinky’ assumption. It has nothing to do with the approximation we made in the prediction step, or the 3 assumptions I listed in the update step. Rather it’s the assumption that the transition map and the measurement map are linear maps.
In the case of a moving keypoint both and were linear. However this is not always the case in more complex systems. Take camera observations as an example. Even ignoring lens distortion, the measurement is still a projective transformation, not a linear one. To understand why, consider the fact that if we move a point very close to a camera 1cm to the left, it might move many pixels on the image. In contrast,if that same point is several meters away then the same movement will result in a change of 1-2 pixels at best.
So why do we need the linearity assumption? Simply put, if is Gaussian then so are and , but this is only true for linear maps. One can approximate and by a Gaussian using a linear approximation of the functions and . However, has its downsides: a) the approximation may be innacurate, and b) computing the linear approximaton requires computing the Jacobian, which may be challenging and computationally expensive.
In summary for a non-linear function and a gaussian we need an effective way to estimate the mean and covariance . One method that always works is Monte-Carlo estimation: we simply take lots random of samples of , and then compute the mean and covariance of . The only issue with this is that we need many samples in order to get an accurate estimate.
Sigma points and the unscented transform
Why rely on random sampling to estimate the mean and covariance of , when we can go with deterministic sampling and pick a robust set of samples . These points are called sigma points. Using these, we can estimate the mean of through a weighted mean . To estimate the covariance we use and a second set of weights to get: . This method is known as the unscented transform (UT). It takes a mean and covariance of a Gaussian and uses sigma points to estimte the mean and covariance of the transformed variable .
So, how do we pick these sigma points and the associated weights and ? Technically, any set of points could work, so long as, if is the identity function, we get the original mean and covariance back. However, most people use a particular algorithm developed by van der Merwe. This algorithm uses three parameters . Given input mean and covariance , the algorithm defines:
Here, is the dimension of and . Note the use of the matrix square root which is well-defined for symmetric positive semidefinite matrices — i.e. covariance matrices. You can calculate the matrix square root for example using the singular value decompositon or the Cholesky decomposition. Here are the equations for the weights:
Since these weights don’t depend on , we only have to compute them once.
In summary, the unscented transform provides a good estimate of the mean and covariance of at the cost of:
- evaluations of the function
- Computing a matrix square root of an matrix (cost: )
In return:
- No need to compute a Jacobian of
- A more accurate estimate if is non-linear
On top of that, the implementation is not difficult.
Finally you may wonder where the name ‘unscented’ came from. As I alluded to, this is simply because creator, Jeffrey Uhlmann, thought the algorithm was cool and “doesn’t stink”.
Unscented Kalman Filter
Armed with the unscented transform, you only need minor modifications to the Kalman filter algorithm to account for non-linear functions. Let’s first look at the predict step as it used to be:
What happens here is that we have as input a Gaussian , we then transform it with to get a Gaussian , and then finally we add some extra noise in the shape of .
Instead of a linear map , we now have a non-linear ‘process model’ . We just have to swap the estimates of the mean and covariance with those provided by the unscented transform:
Here, are the sigma points derived from . While this seems complex, we can rewrite it using the unscented transform to get:
That’s not too bad! This also shows you could actually swap out the unscented transform for any method of estimating the mean/covariance of .
Then what about the predict step? We have our estimate and an observation . Instead of a measurment matrix , we have a measurment function . We start by applying the unscented transform to the estimate to put it in the measurement space:
Then we calculate the ‘cross-variance’ beween and . If are the sigma points associated to , then this cross-variacne is defined by:
The cross-variance takes on the role of the matrix in the original kalman filter. From here we find the Kalman gain as:
Ffinally our new estimate becomes:
And so the unscented kalman filter is born! This concludes the mathematical part of this blog post. Coming up next, we’ll dive into my implemenaton.
</math>
<code>
Let’s put the unscented Kalman filter to work on an actual problem. Not just to see Kalman filters in action, but also to understand why I needed to speed it up.
Model problem
Let’s go back to the beginning of this post. We’re dealing with multiple cameras capturing a person’s movement. A machine learning algorithm is kind enough to give us the ‘keypoints’ on the skeleton of the person (e.g. nose, left elbow, right knee, etc.). Our mision is to turn these 2D pixel positions to 3D coordinates.
To paint a clearer picture, I made a little simulation of a keypoint moving around in 3D projcted down to the viewpoint of two cameras. Below you can see two plots showing what each of the two cameras can see. Thanks to he noise I added the cameras don’t see a smooth curve at all. This is pretty much what you would get when applying machine learning pose detection algorithms on real footage too.
from time import perf_counter
from typing import Callable
import matplotlib.pyplot as plt
import numpy as np
from scipy.ndimage import gaussian_filter1d
from ukf_pyrs import (
UKF,
FirstOrderTransitionFunction,
SigmaPoints,
measurement_function,
transition_function,
UKFParallel,
)
from ukf_pyrs.pinhole_camera import CameraProjector, PinholeCamera
import argparse
N_points = 50
point_a = np.array([-50, 0, 0])
point_b = np.array([0, 120, 130])
point_c = np.array([10, -10, 10]) _ 2
t = np.linspace(0, 1, N_points)
dt = t[1] - t[0]
points = (1 - t)[:, None] _ point_a[None, :] + t[:, None] _ point_b[None, :]
points += (np.cos(t _ np.pi) \*_ 2)[:, None] _ point_c[None, :]
points = points.astype(np.float32)
np.random.seed(0)
rand_scale = 1
points_rand = (points + np.random.randn(_points.shape) _ rand_scale).astype(np.float32)
cam1 = PinholeCamera.from_params(
camera_position=np.array([50, 100, 0]),
lookat_target=np.array([0, 0, 0]),
fov_x_degrees=90,
resolution=np.array([640, 480]),
)
cam2 = PinholeCamera.from_params(
camera_position=np.array([-50, 80, 0]),
lookat_target=np.array([0, 0, 0]),
fov_x_degrees=90,
resolution=np.array([640, 480]),
)
proj_points_obs1 = cam1.project(np.ascontiguousarray(points_rand[0::2])).reshape(-1, 2)
proj_points1 = cam1.project(points).reshape(-1, 2)
proj_points_obs2 = cam2.project(np.ascontiguousarray(points_rand[1::2])).reshape(-1, 2)
proj_points2 = cam2.project(points).reshape(-1, 2)We can then plot this simulation:
plt.figure(figsize=(8, 4))
plt.subplot(1,2,1)
plt.plot(\*proj_points_obs1.T)
plt.xlabel("x")
plt.ylabel("y")
plt.title("View from camera #1")
plt.subplot(1,2,2)
plt.plot(\*proj_points_obs2.T)
plt.xlabel("x")
plt.ylabel("y")
plt.title("View from camera #2")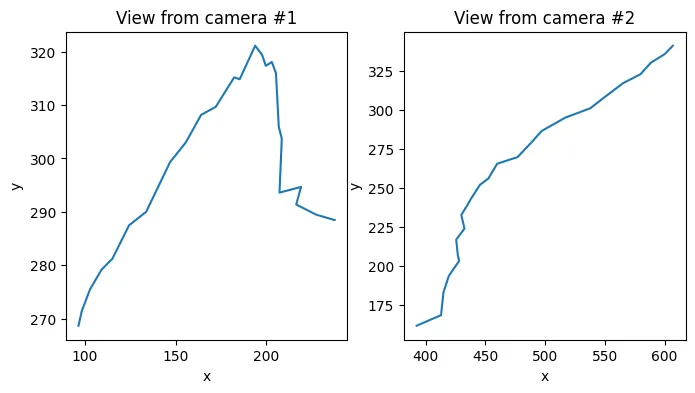
To model this problem we use a model dimension of (that’s position plus vecocity) and a measurement dimension of 2 (the pixels on a screen).
The measurement function takes in two arguments; the position and an integer indicating the camera number (this is something that we’ll get back to later). To turn this function into an object that Rust can understand, we use the @measurement_function decorator. The model transition function is just (again with a decorator to tell Rust what’s going on).
dim_x = 6
dim_z = 2
@measurement_function(dim_z)
def h_py(x: np.ndarray, cam_id: int) -> np.ndarray:
pos = x[:3]
if cam_id == 0:
return cam1.world_to_screen_single(pos)
elif cam_id == 1:
return cam2.world_to_screen_single(pos)
else:
return np.zeros(2, dtype=np.float32)
@transition_function
def f_py(x: np.ndarray, dt: float) -> np.ndarray:
position = x[:3]
velocity = x[3:]
return np.concatenate([position + velocity * dt, velocity])Next we need something to generate sigma points, as well as something to do the heavy lifting of the unscented Kalman filter algorithm. The Kalman filter algorithm needs matrices , and which we’ll need t set as well.
We actually only changed the value of from its default, as and are fine if they’re an identity matrix in this case. If you have a really good theoretical model, you might be able to derive good values for , and . In practice though, you’re just going to have to fiddle around with it until it works.
sigma_points = SigmaPoints.merwe(dim_x, 0.5, 2, -2)
kalman_filter = UKF(dim_x, dim_z, h_py, f_py, sigma_points)
kalman_filter.Q = np.diag([1e-2] * 3 + [3e1] * 3).astype(np.float32)
kalman_filter.R = np.eye(2).astype(np.float32)
kalman_filter.P = np.eye(6).astype(np.float32)Now we’re going to alternatively do a predict and update step from the point of view of either camera. To tell the Kalman filter which camera is making the observation we use the update_measurement_context method. Whatever value we pass here is what’s going to get passed to the measurement function .
predictions_list = []
for p1, p2 in zip(
proj_points_obs1, proj_points_obs2
):
kalman_filter.update_measurement_context(0)
kalman_filter.predict(dt)
kalman_filter.update(p1)
predictions_list.append(kalman_filter.x)
kalman_filter.update_measurement_context(1)
kalman_filter.predict(dt)
kalman_filter.update(p2)
predictions_list.append(kalman_filter.x)
predictions = np.array(predictions_list) # type: ignore
pos_predictions = predictions[:, :3]Then finally we are plotting the result below. We see that the Kalman filter is able to track the keypoint quite well in this problem. After taking a bit of time to settle it even gives an accurate estimate of the velocity of the keypoint!
plt.figure(figsize=(8, 8))
plt.subplot(2, 2, 1)
plt.title("Camera 1 reprojected tracking")
plt.plot(
*cam1.project(np.array(pos_predictions)).reshape(-1, 2).T, ".-", label="Predicted"
)
plt.plot(*proj_points_obs1.T, ".", label="Observed")
plt.plot(\*proj_points1.T, "-", label="True")
plt.legend()
plt.subplot(2, 2, 2)
plt.title("Camera 2 reprojected tracking")
plt.plot(
*cam2.project(np.array(pos_predictions)).reshape(-1, 2).T, ".-", label="Predicted"
)
plt.plot(*proj_points_obs2.T, ".", label="Observed")
plt.plot(\*proj_points2.T, "-", label="True")
plt.legend()
plt.subplot(2, 2, 3)
plt.title("Tracking error (smoothened)")
sigma = 5
tracking_errors = np.linalg.norm(points - pos_predictions, axis=1)
tracking_errors_rand = np.linalg.norm(points_rand - pos_predictions, axis=1)
plt.plot(
gaussian_filter1d(tracking_errors, sigma),
label="Unperturbed",
)
plt.plot(
gaussian_filter1d(tracking_errors_rand, sigma),
label="Perturbed",
)
plt.ylim(0, np.mean(tracking_errors) \* 2)
plt.legend()
plt.subplot(2, 2, 4)
plt.title("Tracking of velocity")
colors = plt.rcParams["axes.prop_cycle"].by_key()["color"]
names = ["x", "y", "z"]
for i, v in enumerate(predictions[:, 3:].T):
plt.plot(v, color=colors[i], label=names[i])
velocity = np.diff(points, axis=0) / dt
for i, v in enumerate(velocity.T):
plt.plot(v, color=colors[i], linestyle="--")
plt.legend()
plt.show()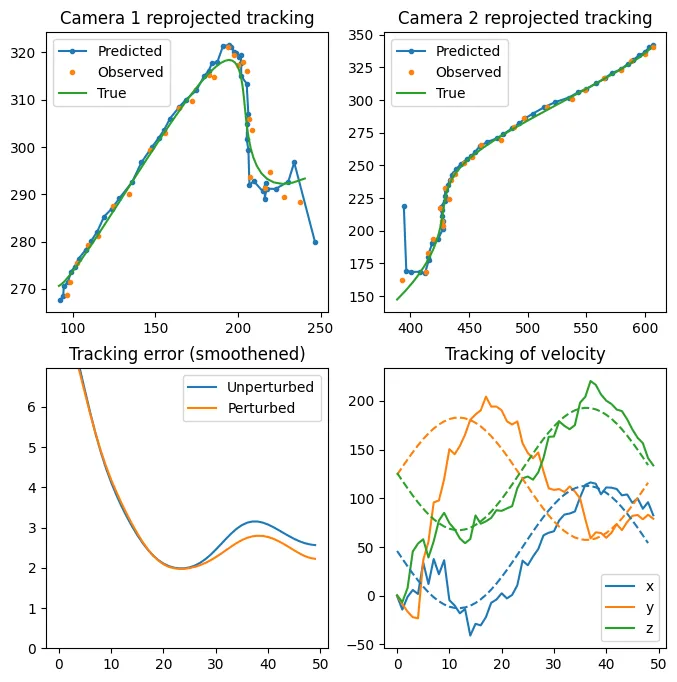
Make it blazingly fast
The implementation above was actually already fully in Rust, and is a lot faster than the Python library filterpy which I based my implementation on. But maybe you noticed that I still used Python to define the measurement and transition funcions. My Rust implementation actually calls these Python functions directly. This is fantastic if you are in a design stage (i.e., you don’t know which function you need precisely), but calling these Python functions comes with a significant overhead.
Fortunately it’s not a lot of work to make Rust implementations of these functions and use those instead. To make it more interesting, we will be tracking not just a single keypoint, but 30 keypoints in parallel. This is much closer to the actual use case because a skeleton consists of many keypoints.
Rather than looking at the accuracy, we’re just looking at speed.
from time import perf_counter
import matplotlib.pyplot as plt
import numpy as np
from scipy.ndimage import gaussian_filter1d
from ukf_pyrs import (
UKF,
FirstOrderTransitionFunction,
SigmaPoints,
measurement_function,
transition_function,
UKFParallel,
)
from ukf_pyrs.pinhole_camera import CameraProjector, PinholeCamera
import argparse
N_points = 10000
point_a = np.array([-50, 0, 0])
point_b = np.array([0, 120, 130])
point_c = np.array([10, -10, 10]) _ 2
t = np.linspace(0, 1, N_points)
dt = t[1] - t[0]
points = (1 - t)[:, None] _ point_a[None, :] + t[:, None] _ point_b[None, :]
points += (np.cos(t _ np.pi) \*_ 2)[:, None] _ point_c[None, :]
points = points.astype(np.float32)
np.random.seed(0)
rand_scale = 1
points_rand = (points + np.random.randn(_points.shape) _ rand_scale).astype(np.float32)
cam1 = PinholeCamera.from_params(
camera_position=np.array([50, 100, 0]),
lookat_target=np.array([0, 0, 0]),
fov_x_degrees=90,
resolution=np.array([640, 480]),
)
cam2 = PinholeCamera.from_params(
camera_position=np.array([-50, 80, 0]),
lookat_target=np.array([0, 0, 0]),
fov_x_degrees=90,
resolution=np.array([640, 480]),
)
proj_points_obs1 = cam1.project(np.ascontiguousarray(points_rand[0::2])).reshape(-1, 2)
proj_points1 = cam1.project(points).reshape(-1, 2)
proj_points_obs2 = cam2.project(np.ascontiguousarray(points_rand[1::2])).reshape(-1, 2)
proj_points2 = cam2.project(points).reshape(-1, 2)
cam1 = PinholeCamera.from_params(
camera_position=np.array([50, 100, 0]),
lookat_target=np.array([0, 0, 0]),
fov_x_degrees=90,
resolution=np.array([640, 480]),
)
cam2 = PinholeCamera.from_params(
camera_position=np.array([-50, 80, 0]),
lookat_target=np.array([0, 0, 0]),
fov_x_degrees=90,
resolution=np.array([640, 480]),
)
hx_rust = CameraProjector([cam1.to_rust(), cam2.to_rust()])
fx_rust = FirstOrderTransitionFunction(3)
sigma_points = SigmaPoints.merwe(6, 0.5, 2, -2)
kalman*filters = []
n_filters = 30
for * in range(n_filters):
kalman_filter = UKF(6, 2, hx_rust, fx_rust, sigma_points)
kalman_filter.Q = np.diag([1] _ 3 + [3e3] _ 3).astype(np.float32)
kalman_filter.Q _= 1e-2
kalman_filter.R = np.diag([1, 1]).astype(np.float32) _ 1e0
kalman_filter.P = np.diag([1e0] _ 3 + [1e0] _ 3).astype(np.float32)
kalman_filters.append(kalman_filter)
time_begin = perf_counter()
parallel_ukf = UKFParallel(kalman_filters)
for p1, p2 in zip(
proj_points_obs1.astype(np.float32), proj_points_obs2.astype(np.float32)
):
parallel_ukf.update_measurement_context([0] \* n_filters)
parallel_ukf.predict(dt)
parallel_ukf.update([p1 + i for i in range(n_filters)])
parallel_ukf.update_measurement_context([1] * n_filters)
parallel_ukf.predict(dt)
parallel_ukf.update([p2 + i for i in range(n_filters)])
time_end = perf_counter()
total_keypoints = n_filters * len(proj_points_obs1) *2
time_per_keypoint_rust = (time_end - time_begin) / total_keypoints
print(f"Time per keypoint (Rust): {time_per_keypoint_rust\*1e6:0.1f} µs")Output
Time per keypoint (Rust): 8.1 µs
hx_rust = CameraProjector([cam1.to_rust(), cam2.to_rust()])
fx_rust = FirstOrderTransitionFunction(3)
sigma_points = SigmaPoints.merwe(6, 0.5, 2, -2)
kalman*filters = []
n_filters = 30
n_points_py = 200
for * in range(n_filters):
kalman_filter = UKF(6, 2, h_py, f_py, sigma_points)
kalman_filter.Q = np.diag([1] _ 3 + [3e3] _ 3).astype(np.float32)
kalman_filter.Q _= 1e-2
kalman_filter.R = np.diag([1, 1]).astype(np.float32) _ 1e0
kalman_filter.P = np.diag([1e0] _ 3 + [1e0] _ 3).astype(np.float32)
kalman_filters.append(kalman_filter)
time_begin = perf_counter()
parallel_ukf = UKFParallel(kalman_filters)
for p1, p2 in zip(
proj_points_obs1[:n_points_py].astype(np.float32), proj_points_obs2[:n_points_py].astype(np.float32)
):
parallel_ukf.update_measurement_context([0] \* n_filters)
parallel_ukf.predict(dt)
parallel_ukf.update([p1 + i for i in range(n_filters)])
parallel_ukf.update_measurement_context([1] * n_filters)
parallel_ukf.predict(dt)
parallel_ukf.update([p2 + i for i in range(n_filters)])
total_keypoints = n_points_py*2 *n_filters
time_end = perf_counter()
time_per_keypoint_py = (time_end - time_begin) / total_keypoints
print(f"Time per keypoint (Python): {time_per_keypoint_py\*1e6:0.1f} µs")
rust_speedup = time_per_keypoint_py / time_per_keypoint_rust
print(f"Rust speedup: {rust_speedup:0.1f}x")
Output
Time per keypoint (Python}: 120.4 µs Rust speedup: 14.9x
That’s 15x speedup just for changing out a python functon for a Rust one! Here I used UKFParallel which takes a list of unscented Kalman filters as input, and allows calling the update/predict functions for each Kalman filter in a batch. This is better than than using a for loop in Python, since we can limit the time spent interacting with the GIL.
Originally the idea of UKFParallel was to actually evaluate the predict / update functions in parallel. Unfortunately, even when the the measurement and transition functions are Rust native, we still end up waiting most of the time for Python to release the GIL. The design decision to make it very easy to use from python also means that proper parallelization requires redesigning parts of the codebase.
But more importantly, how does this compare to filterpy?
from filterpy.kalman import UnscentedKalmanFilter
from filterpy.kalman.sigma_points import MerweScaledSigmaPoints
dim_x = 6
dim_z = 2
sigma_points = MerweScaledSigmaPoints(n=6, alpha=0.5, beta=2, kappa=-2)
def fx(x, dt):
x = x.copy()
x[:3] += x[3:6] _ dt
return x
ukf = UnscentedKalmanFilter(
dim_x=dim_x,
dim_z=dim_z,
dt=dt,
fx=fx,
hx=None,
points=sigma_points,
)
ukf.Q=np.diag([1] _ 3 + [3e3] * 3)*1e-2
ukf.R=np.eye(dim_z)
ukf.P=np.diag([1] _ 3 + [3e3] _ 3)
def make_measerument_functon(cam:PinholeCamera)->Callable[[np.ndarray],np.ndarray]:
def hx(x):
return cam.world_to_screen_single(x[:3])
return hx
hx1 = make_measerument_functon(cam1)
hx2 = make_measerument_functon(cam2)
time_begin = perf_counter()
for obs1,obs2 in zip(proj_points_obs1, proj_points_obs2):
try:
ukf.predict(dt)
except np.linalg.LinAlgError:
pass
ukf.hx = hx1
ukf.update(obs1)
try:
ukf.predict(dt)
except np.linalg.LinAlgError:
pass
ukf.hx = hx2
time_end = perf_counter()
n_keypoints = len(proj_points_obs1) *2
time_per_keypoint_filterpy = (time_end - time_begin) / n_keypoints
print(f"Time per keypoint (filterpy): {time_per_keypoint_filterpy*1e6:0.1f} µs")
print(f"Rust speedup: {time_per_keypoint_filterpy / time_per_keypoint_rust:.1f}x")
Output
Time per keypoint (filterpy): 176.4 µs Rust speedup: 21.8x
We see that filterpy is around 22x times slower than my implementation using Rust native functions. Furthermore, (on this computer) we would spend around 5ms to process 30 keypoints using the filterpy implementation (without multithreading). In practice this means that if we’re processing data from a 30fps camera stream, we would be spending roughly 1/6th of a frame just on the Kalman filter logic. With the Rust implementation this is only 1/137th of a frame — which gives us much more time for other logic. Since we’re processing data from multiple camera streams in parallel, this is a big deal!
Thoughts on using Rust
This was my first project using Rust and I learned a lot. Not all of my experiences were positive, and I also made some design decisions which I have come to regret. Here are some of my thoughts.
The Measurement function trait
I think Rusts trait system is honestly amazing. All ‘classes’ are just structs which make it extremely clear what all the data is that a ‘class’ uses in its lifetime. Abstract interaction between classes is then done by implementing certain traits.
For example in my code I defined a MeasurementFunction trait, and the unscented Kalman filter then gets told which measurement function to use at runtime by taking a Box<dyn MeasurementFunction>. This was very important because this way I was able to treat measurement functions defined in Python and those defined in Rust on equal footing. This feature was in fact the hardest thing for me to figure out in this project.
One of the reasons we needed this is because measurement functions need context in my usecase. In particular, when we run the update function we need to know for which camera to run this function. There are multiple ways to make this possible, but since I wanted to avoid restrictions on what this context could be, it became a bit of a headache dealing with this.
When using a Kalman filter it is normal to have different sensors (such as different cameras), which means having a different measurement function for each sensor. If the number of sensors is finite, then we don’t actually need an arbitrary object as context. We just need to keep a list of all the measurement functions, and then the only context we need is a single index. Had I made this design decision, my code would likely have been much simpler.
PyO3
C/C++ with a together with a library like pybind is still the go-to for speedin up your Python code. With the PyO3 crate, Rust offers itself as a solid alternative. Defining classes and methods, calling Python code, handling errors, and dealing with the GIL is relatively easy. I think what makes this possible is Rust’s first-class macro system. Still, you do end up with a fair bit of boilerplate. For instance, you need to define getters and setters for every single attribute that you want to expose to Python. As an example, I ended up with 143 lines of code that looks like this in the unscented Kalman filter class alone:
#[getter]
#[pyo3(name = "x")]
pub fn py_get_x(&self, py: Python<'_>) -> PyResult<Py<PyArray1<Float>>> {
let array = self.x.clone().into_pyarray(py).to_owned();
Ok(array)
}
#[setter]
#[pyo3(name = "x")]
pub fn py_set_x(&mut self, x: PyReadonlyArray1<Float>) -> PyResult<()> {
self.x = x.as_array().to_owned();
Ok(())
}I understand why it’s necessary, but that doesn’t make it fun.
Furthermore, Rust has good support for generic types. There were quite a few places where defining a struct or trait with generic types would have made my life easier, but this is not supported by PyO3 (at least for now).
As the ecosystem matures a little, I have no doubt things are going to improve even further. But for now, while it isn’t difficult per se, it still can be a bit tedious to write Python modules in Rust.
ndarray vs numpy
One reason why I really enjoy writing numerical code in Python is because of numpy and its surrounding ecosystem. Rust is faster, but without good libraries for numerical array programming, it would not be so useful for me. The main library in this area is the ndarray crate and, as a whole, it is intended to be quite similar to numpy. However, with Rust’s strict typing and memory management, I did find it quite tricky at times.
For instance, in Python we might write x+=K@y, but with ndarray we write x += &K.dot(&y), although this might change depending on whether K or y are an Array, ArrayView or ArrayViewMut, and sometimes we have to call .view(), .to_owned() or .clone() on the arrays, and sometimes we don’t. Certainly at first, but still now sometimes, it just feels like trial and error is necessary to do simple things like add or multiple two arrays. However, many of these things are good; we’re making it really explicit when a memory copy occurs, and we are also making sure that each piece of data has only one owner. This prevents bugs and improves performance. On the other hand, it can also be very frustrating at first when coming from a language like Python where you never have to worry about that (for better or for worse).
Profiling
Whenever writing code were speed matters, profiling is your best friend. In this particular project I was using pyspy, which can also inspect native code. It basically polls the state of the program 100 times per second and records which function or line of code the program was executing, even if that code was written and compiled in another language like Rust. You then look at what part of the code take up most of the excecution time, and try to improve those first. Before profiling my code was around 3-4 times slower than it is now. Most of the performance left on the table was due to mistakes such as unnecessary memory copies or iterating over an array in a non-contiguous manner (i.e. column-by-column rather than row-by-row). There are still improvements I can make to my implementation, but I was optimizing the code right before my wife went into labor, and after that I had other priorities for a while.
Conclusion
Rust is a pretty compelling tool for writing fast code as part of a larger Python code base. I like the language, and I am eager to use more of it. I don’t know if the unscented Kalman filter implementation I made will actually end up getting used at my workplace, but it was a nice learning experience regardless. It was also very interesting to actually dive deeper into how (unscented) Kalman filters work, rather than just using them as a tool.
I hope you learned something about Kalman filters, and I’m eager to know how you will use Rust to speed up some of your Python codebse!
Keep reading

1st of May, 2023
I made an interactive dashboard for this website, and here is the story of how I did it.

1st of August, 2024
Self-hosting your own cloud services not only saves money, it is also a great way to learn

13th of February, 2021
I have 15 years worth of email traffic data, let's take a closer look and discover some fascinating patterns.

9th of November, 2020
We use exams to determine how much a student knows, but exams aren't perfect. How can we estimate the uncertainty in students' exams scores?

26th of August, 2020
Cross validation is extremely important, but how should we choose the size of our validation and test sets?

12th of August, 2020
I use last.fm to track my music listening. Let's look at my data to discover how my musical preferences evolve over time.
10th of August, 2020
Normally distributed data is great, but how do you know whether your data is normally distributed?

20th of June, 2020
Judging in figure skating is biased. Let's use data science to figure out just how bad the issue is.

15th of January, 2025
I made an array programming language as a language extension to Rust

26th of February, 2023
Read this blog post if you're curious what I worked on during my PhD!

29th of March, 2022
Linear least-squares system pop up everywhere, and there are many fast way to solve them. We'll be looking at one such way: GMRES.

10th of March, 2022
We recently made a paper about supervised machine learning using tensors, here's the gist of how this works.
26th of September, 2021
A lot of data is naturally of 'low rank'. I will explain what this means, and how to exploit this fact.

29th of August, 2021
Parsing and editing Word documents automatically can be extremely useful, but doing it in Python is not that straightforward.

31st of May, 2021
Finally, let's look at how we can automatically sharpen images, without knowing how they were blurred in the first place.

2nd of May, 2021
Deconvolving and sharpening images is actually pretty tricky. Let's have a look at some more advanced methods for deconvolution.

9th of April, 2021
In order to automatically sharpen images, we need to first understand how a computer can judge how 'natural' an image looks.

13th of March, 2021
Deconvolution is one of the cornerstones of image processing. Let's take a look at how it works.
